Template : GitHub Link.
TCLR structure
Please refer to the literature link for the structure of the TCLR model 🔗 TCLR Link.
Intro / 说明
以 Cao 等人 (Paper Link) 的文章内容为例:
论文提出一个氧化的Arrhenius方程,描述铁素体-马氏体钢的氧化行为,并预测不同合金的氧化结果。这里省略热力学项后,采用以下动力学公式描述Cao 等人 所提出的泛化氧化热动力学方程:
formula 1 : ln(W) = n x ln(t) + ln(K)
其中 :
W 为氧化增重 (mg/dm^2) | K 为动力学常数 | n 为时间指数 | t 为腐蚀时间 (h)
formula 1 为动力学方程 formula 2 的对数形式
formula 2 : W = K x t ^n
formula 2 用以形容某特定合金的氧化过程 : 氧化增重随着时间的变化情况
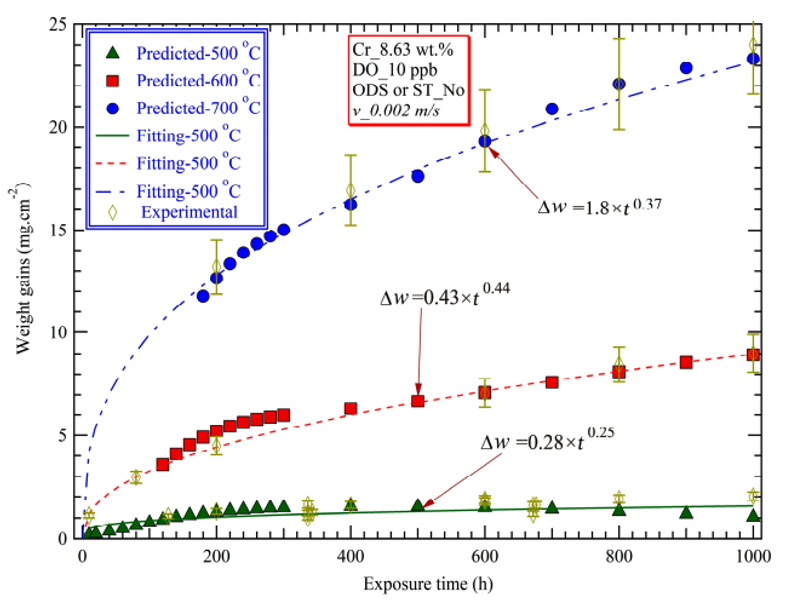 (图1 : 图片来源)
(图1 : 图片来源)
时间指数 n 受到合金组成元素(Cr、Fe、Mn、...(wt.%))、测试条件(i.e., 温度T(K) 等)的影响
在Cao 等人 (Paper Link) 的工作中, 他们通过寻找时间指数n和合金组成元素、测试条件的可视化映射, 建立描述合金氧化/腐蚀的统一表达形式, 即寻找公式 f, 使得 :
formula 3 : n = f(Cr、Fe、Mn、...、T、...)
但是, n作为氧化数据集合中的隐藏特征,是难于被捕捉的。在腐蚀试验中, 需要通过控制单一变量的一组合金氧化样本, 得到一个时间指数样本。 如 Table E0 所示:
| Num | fixed | single variable | tests | n |
|---|---|---|---|---|
| 1 | Fe、Mn、...、T、... | Cr = Cr0 | 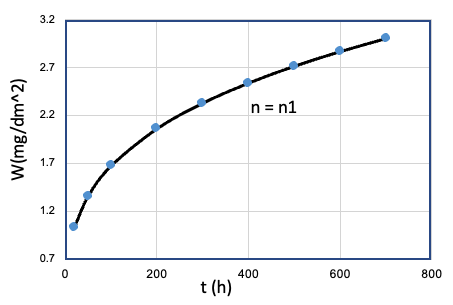 |
n1 |
| 2 | Fe、Mn、...、T、... | Cr = Cr1 | 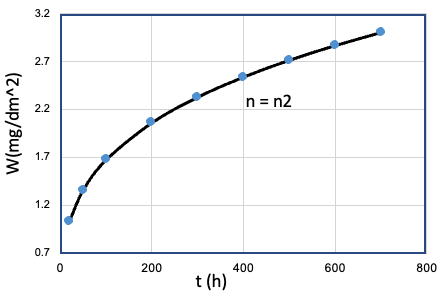 |
n2 |
| ... | ... | ... | ... | ... |
| 10 | Fe、Mn、...、T、... | Cr = Cr10 | 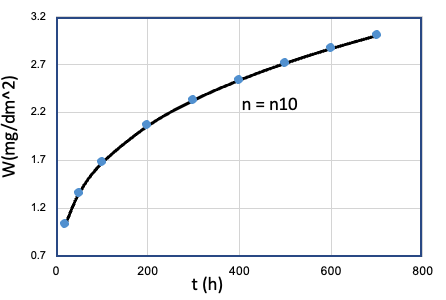 |
n10 |
| 11 | Cr、Mn、...、T、... | Fe = Fe0 | 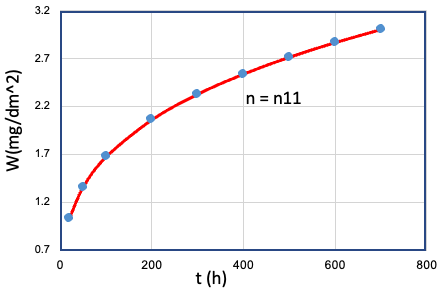 |
n11 |
| 12 | Cr、Mn、...、T、... | Fe = Fe1 | 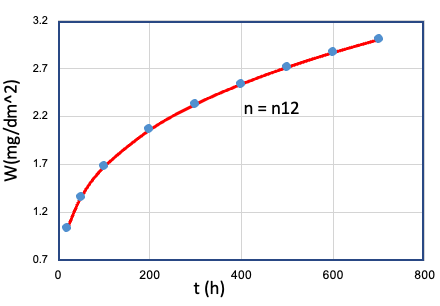 |
n12 |
| ... | ... | ... | ... | ... |
| 20 | Cr、Mn、...、T、... | Fe = Fe10 | 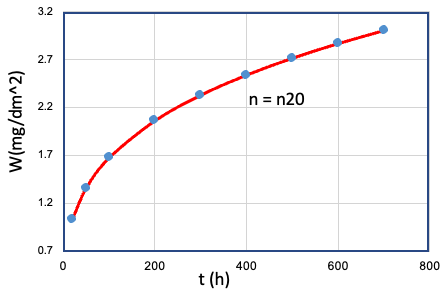 |
n20 |
| ... | ... | ... | ... | ... |
Table E0 中每一组数据,均是在控制单一变量下给定的一组氧化实验的结果。想要研究变量 Cr、Fe、Mn、...、T、... 与时间指数n的关系, 需要测试不同给定条件下(fixed)每一个变量(single variable)在不同水平下的多组氧化增重测量(test)。实验上几乎不可能提供如此巨大的实验样本。
故TCLR被提出, 解决这一问题。
Table E1 中 w(mg/dm^2) 氧化增重是直接可测变量,通过实验积累可以得到如 Table E1 所示的氧化数据集合(假设集合大小为200)
| Num | Cr (wt.%) | Fe (wt.%) | Mn (wt.%) | ... | T (K) | t (h) | w(mg/dm^2) |
|---|---|---|---|---|---|---|---|
| 1 | . | . | . | . | . | . | w1 |
| 2 | . | . | . | . | . | . | w2 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 200 | . | . | . | . | . | . | w200 |
按照 formula 1 对原始变量取对数处理得到Table E2
| Num | Cr (wt.%) | Fe (wt.%) | Mn (wt.%) | ... | T (K) | ln(t) (h) | ln(w)(mg/dm^2) |
|---|---|---|---|---|---|---|---|
| 1 | . | . | . | . | . | . | ln(w1) |
| 2 | . | . | . | . | . | . | ln(w2) |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 200 | . | . | . | . | . | . | ln(w200) |
根据 formula 1 的结果可知, ln(W) 和 ln(t) 的斜率即为时间指数 n
TCLR 将Table E2中所有数据根据其特征的不同划分为不同的子集, 称为一个叶子, 在每个叶子上, 数据均符合同一个时间指数n的描述,即满足同一个动力学方程。
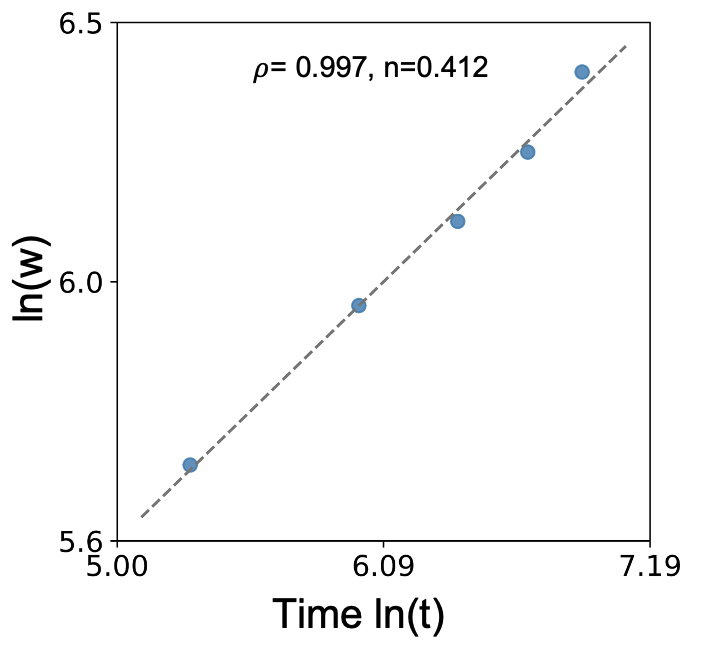 (图2 :图片来源)
(图2 :图片来源)
图中的数据点具有不同的特征 Cr、Fe、Mn、...、T、..., 且都满足同一个动力学方程指数n。故可以轻易的得到两者之间的映射关系。 这种关系可以被公式化或者模型化(通过代理模型描述), 最终得到 formula 3。基于此, Cao 等人 建立了用于描述多种合金在多种测试条件下氧化行为的统一方程。
Template/ 调用模版
#coding=utf-8
from TCLR import TCLRalgorithm as model
dataSet = "testdata.csv"
correlation = 'PearsonR(+)'
minsize = 3
threshold = 0.9
split_tol = 0.8
model.start(filePath = dataSet, correlation = correlation, minsize = minsize, threshold = threshold,
mininc = mininc ,split_tol = split_tol,)
Output 运行结果:
-
classification structure tree in pdf format (Result of TCLR.pdf) 图形结果
-
a folder called 'Segmented' for saving the subdataset of each leaf (passed test) 数据文件
| Result | classification structure | folder |
|---|---|---|
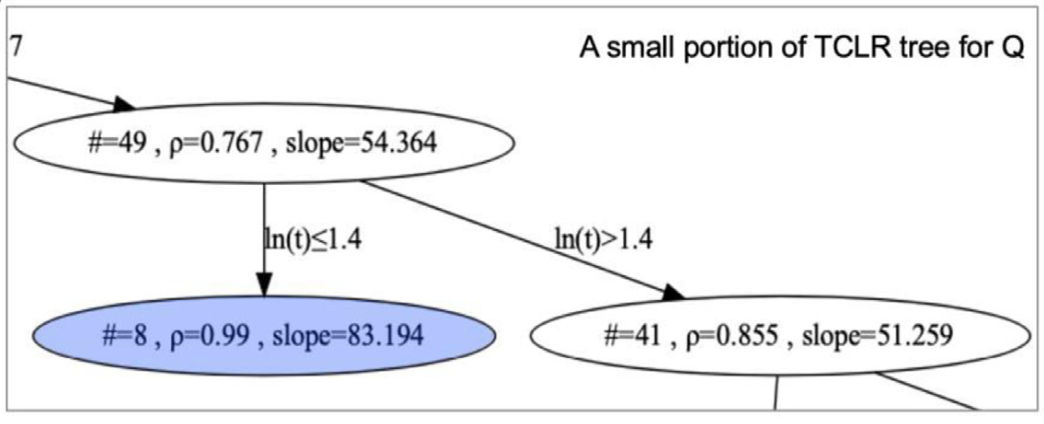 |
 |
TCLR 的必要参数包括 : dataSet 、 correlation 、minsize 、threshold
dataSet- 所研究的数据集合「Table E2」.correlation- TCLR特征和TCLR变量的关联.minsize- TCLR结构树叶子上最小数据量threshold- 准停阈值
dataSet :
传入数据集合Table E2。 Table E2需要将具有隐藏关系的特征放置于最后两列。例如在上述问题中, 对数的时间 ln(t) 和对数的增重 ln(W) 包含隐变量 : ln(W) = n x ln(t) + ln(K), 故 变量ln(t)放置在倒数第二列, 响应ln(W)放置在倒数第一列。
correlation :
定义变量之间的关联, 在本例中, ln(W) vs. ln(t) --> n 是线性的, 且 n>0, 故定义correlation = 'PearsonR(+)' 捕捉正相关线性关系。
TCLR 中定义 correlation : {'PearsonR(+)','PearsonR(-)',''MIC','R2'} :
- 'PearsonR(+)' : 捕捉正相关线性关系
- 'PearsonR(-)' : 捕捉负相关线性关系
- 'MIC' : 捕捉非线性关系
- 'R2' : 捕捉非线性关系
minsize :
每个叶子上最小的数据量。因为TCLR通过变量ln(W) vs. ln(t)得到斜率 n, minsize 通过限制直线上数据点的个数来得到准确的斜率 n。 默认minsize=3, 即图2中一条直线上最少有三个不同取值的时间ln(t)。
threshold :
每个叶子上数据通过同一个时间指数n描述的一致性。threshold = 1, 则叶子上所有数据均严格地落在一条直线上。默认threshold = 0.9, 因为数据均是有噪声的, 很难理想的通过一条直线完美拟合。如果 threshold 太大,如(0.99,0.98), 会导致大量的数据难以满足此苛刻的条件,而无法在TCLR中被合理地分开。